



ya they show someone in prison for life a naughty little girl pic and if they get a bonner then they're pedo. kinda silly considering reproducing at a younger age had been normal through most of human history in most of the world. would make more sense to look at convicted pedos since theyve committed the crime.
wondering if it's, pre-puberty, or pre-18yo, or something else entirely.

@fluffy @Terry @p @Dave Here's the titles and more info on them, and here's a link to the MS
https://www.ipce.info/sites/ipce.info/files/biblio_attachments/every_fifth.pdf

{kind=link}
{kind=link}
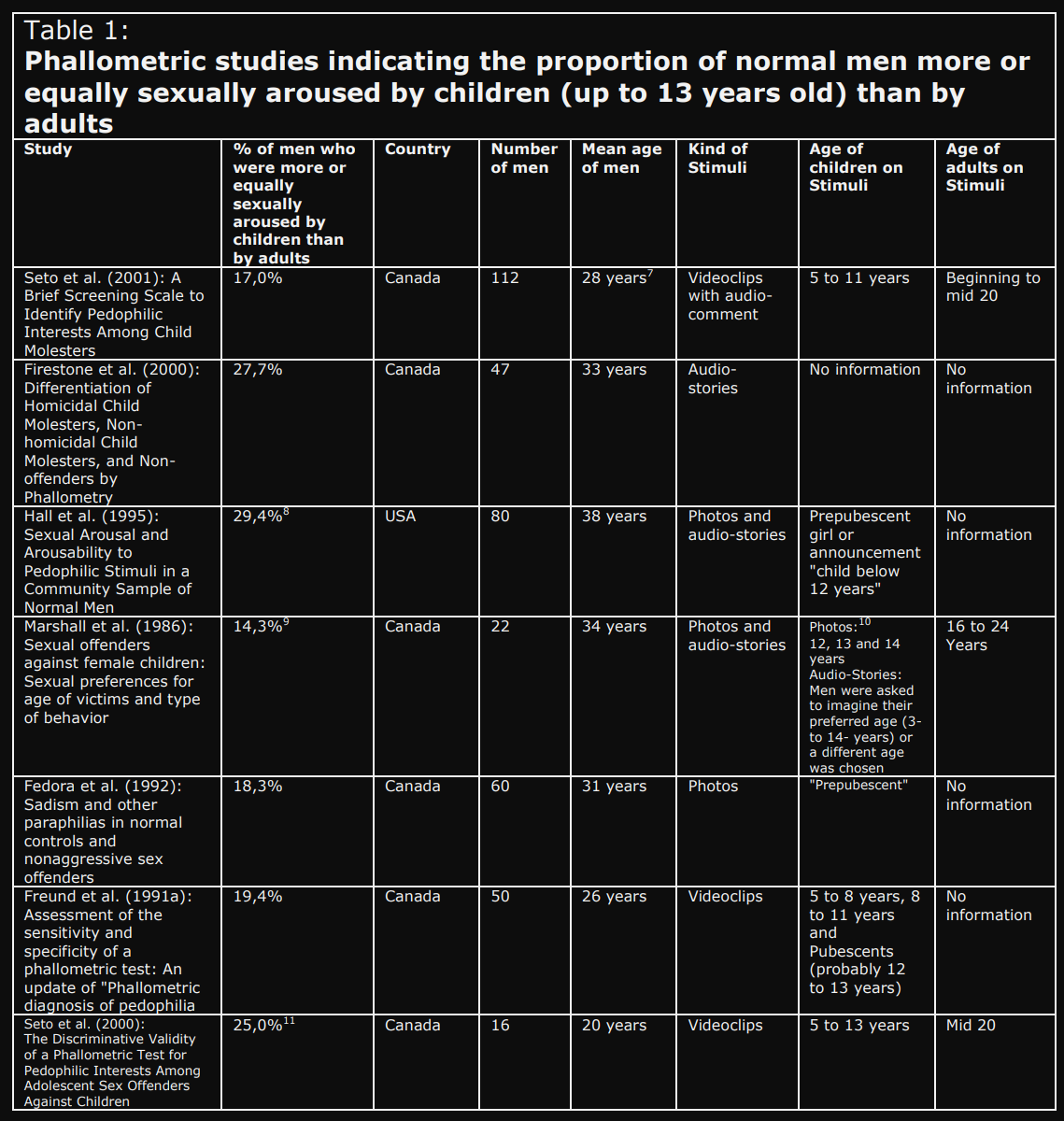
> number of men: Only one is over 100
This is a ridiculously small sample size.
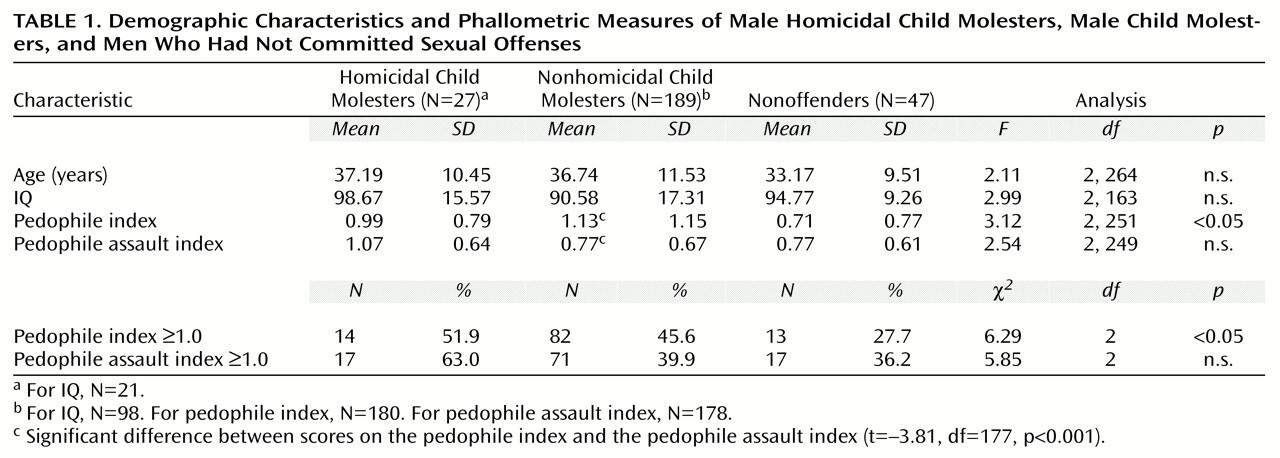
@lanodan @Terry @p @Dave @fluffy It really isn't. First, there are 7 of these studies, with a combined sample of 387. But the actual validity of the result you get depends on the values you get. These aren't weak values, so the chances of them being completely wrong is low, but the authors calculate the p value anyway, in Firestone 2000 it's <0.05
{kind=link}
> combined sample of 387
Lol, as if you could just add different statistics together like that, in programming this would be a fucking Type Error. Don't be JavaScript.
@lanodan @Terry @p @Dave @fluffy This is a valid thing people do. They take multiple studies and get a value by weighing them by their samples
I remember it here as an example from a really good paper
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4739500/pdf/emss-66004.pdf
As an example, a review of the world’s literature on intelligence, which included 10,000
pairs of twins, showed that identical twins are significantly more similar than fraternal twins,
with twin correlations of about 0.85 and 0.60, respectively, with corroborating results from
family and adoption studies, implying significant genetic influence (Bouchard & McGue,
1981, as modified by Loehlin, 1989)
@lanodan @Terry @p @Dave @fluffy When they actually do it they account for any differences, exclude based on criteria, correct for X, Y, and Z, etc, etc, but the point still stands that if a series of studies get numbers significantly higher than people generally think (1-2%), it's very very unlikely it's random chance
